
Reconnaissance Image définition
La première question que vous vous posez peut-être est de savoir quelle est la différence entre la computer vision et la reconnaissance d’images. En effet, la vision par ordinateur a été vigoureusement développée par Google, Amazon et de nombreux développeurs de l’Intelligence Artificielle, et les deux termes « vision par ordinateur » et « reconnaissance d’images » peuvent avoir été utilisés de manière interchangeable. La Computer Vision (CV) consiste à laisser un ordinateur imiter la vision humaine et agir. Par exemple, la CV peut être conçue pour détecter un enfant qui court sur la route et produire un signal d’avertissement pour le conducteur. En revanche, la reconnaissance d’images consiste à analyser les pixels et les formes d’une image pour reconnaître l’image comme un objet particulier. La vision par ordinateur signifie qu’elle peut « faire quelque chose » avec les images reconnues.
Qu’est-ce que la reconnaissance d’images ?
Comme le dit la phrase « Ce que vous voyez est ce que vous obtenez », le cerveau humain facilite la vision. Il n’est pas nécessaire de faire un effort pour distinguer un chien, un chat ou une soucoupe volante. Mais ce processus est assez difficile à imiter pour un ordinateur : il ne semble facile que parce que notre cerveau est incroyablement doué pour reconnaître les images. Un exemple courant de reconnaissance d’images est la reconnaissance optique de caractères (OCR). Un scanner peut identifier les caractères de l’image pour convertir les textes d’une image en un fichier texte. Avec le même procédé, l’OCR peut être appliquée pour reconnaître le texte d’une plaque d’immatriculation dans une image.
Comment fonctionne la reconnaissance d’images ?
Comment former un ordinateur à distinguer une image d’une autre image ? Le processus d’un modèle de reconnaissance d’image n’est pas différent du processus de modélisation par machine learning. Nous énumérerons le processus de modélisation pour la reconnaissance d’images dans les étapes 1 à 4.
Modélisation Étape 1 : Extraire les caractéristiques des pixels d’une image
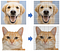
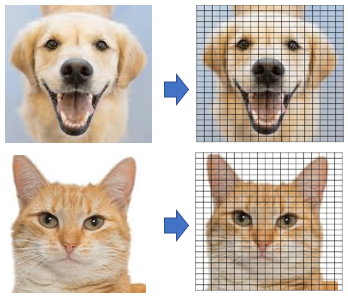
Tout d’abord, un grand nombre de caractéristiques, appelées traits, sont extraites de l’image. Une image est en fait constituée de « pixels », comme le montre la figure (A). Chaque pixel est représenté par un nombre ou un ensemble de nombres – et la plage de ces nombres est appelée la profondeur de couleur (ou profondeur de bits). En d’autres termes, la profondeur de couleur indique le nombre maximum de couleurs potentielles qui peuvent être utilisées dans une image. Dans une image (8 bits) en niveaux de gris (noir et blanc), chaque pixel a une valeur qui va de 0 à 255. La plupart des images utilisent aujourd’hui des couleurs de 24 bits ou plus. Une image en couleur RVB signifie que la couleur d’un pixel est la combinaison du rouge, du vert et du bleu. Chacune de ces couleurs a une valeur comprise entre 0 et 255. Ce générateur de couleurs RVB montre comment n’importe quelle couleur peut être générée par RVB. Ainsi, un pixel contient un ensemble de trois valeurs RGB(102, 255, 102) se réfère à la couleur #66ff66. Une image de 800 pixels de large, 600 pixels de haut a 800 x 600 = 480 000 pixels = 0,48 mégapixels (« mégapixel » est 1 million de pixels). Une image d’une résolution de 1024×768 est une grille de 1 024 colonnes et 768 lignes, qui contient donc 1 024 × 768 = 0,78 mégapixels.
Modélisation Étape 2 : Préparer des images étiquetées pour former le modèle

Figure (B)
Une fois que chaque image est convertie en milliers de caractéristiques, avec les étiquettes connues des images, nous pouvons les utiliser pour former un modèle. La figure (B) montre de nombreuses images étiquetées qui appartiennent à différentes catégories telles que « chien » ou « poisson ». Plus nous pouvons utiliser d’images pour chaque catégorie, mieux un modèle peut être entraîné à dire à une image si c’est une image de chien ou de poisson. Dans ce cas, nous connaissons déjà la catégorie à laquelle appartient une image et nous l’utilisons pour entraîner le modèle. C’est ce qu’on appelle le « machine learning » supervisé.
Modélisation Étape 3 : Entraîner le modèle à catégoriser les images

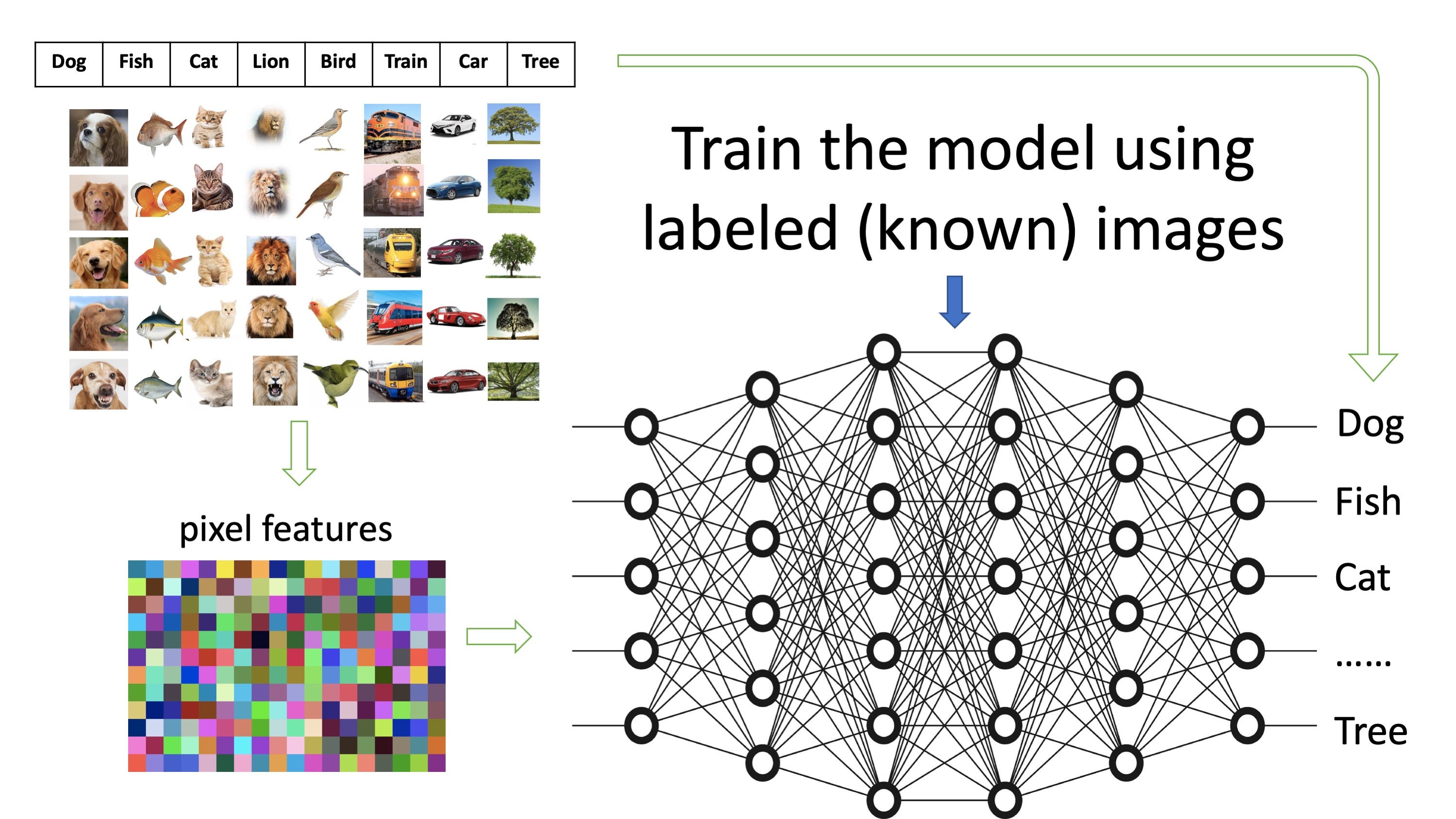
Figure (C)
La figure (C) montre comment un modèle est entraîné avec les images pré-étiquetées. Les énormes réseaux au milieu peuvent être considérés comme un filtre géant. Les images dans leurs formes extraites entrent du côté de l’entrée et les étiquettes sont du côté de la sortie. L’objectif est de former les réseaux de telle sorte qu’une image avec ses caractéristiques provenant de l’entrée corresponde à l’étiquette de droite.
Étape de modélisation 4 : Reconnaître (ou prédire) qu’une nouvelle image fait partie des catégories
Une fois qu’un modèle est formé, il peut être utilisé pour reconnaître (ou prédire) une image inconnue. La figure (D) montre qu’une nouvelle image est reconnue comme une image de chien. Notez que la nouvelle image passera également par le processus d’extraction des caractéristiques des pixels.

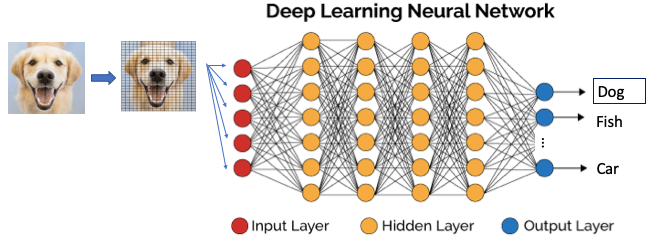
Convolution Neural Networks – l’algorithme de reconnaissance d’images
Les réseaux de la figure (C) ou (D) ont laissé entendre que les modèles les plus populaires sont des modèles de réseaux neuronaux. Les Convolution Neural Networks (CNNs ou ConvNets) ont été largement appliqués dans la classification d’images, la détection d’objets ou la reconnaissance d’images.
Une explication en douceur des Convolution Neural Networks
Je vais utiliser les images des chiffres de l’écriture manuscrite du MNIST pour expliquer les CNN. Les images du MNIST sont des images en noir et blanc de forme libre pour les chiffres de 0 à 9. Il est plus facile d’expliquer le concept avec l’image en noir et blanc car chaque pixel n’a qu’une seule valeur (de 0 à 255) (notez qu’une image en couleur a trois valeurs dans chaque pixel).
La couche réseau des CNN est différente des réseaux de neurones typiques. Il existe quatre types de couches : la convolution, les ReLU, la mise en commun et les couches entièrement connectées, comme le montre la figure (E). Que fait chacun des quatre types de couches ? Laissez-moi vous expliquer.


- Convolution layer

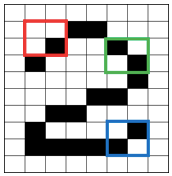
Figure (F)
La première étape que font les CNN est de créer de nombreuses petites pièces appelées « features » comme les boîtes 2×2. Pour visualiser le processus, j’utilise trois couleurs pour représenter les trois caractéristiques de la figure (F). Chaque élément caractérise une forme de l’image originale.
Laissez chaque élément balayer l’image originale. S’il y a une correspondance parfaite, il y a un score élevé dans cette case. S’il y a une correspondance faible ou aucune correspondance, la note est faible ou nulle. Ce processus de production des scores est appelé filtrage.


Figure (G)
La figure (G) montre les trois caractéristiques. Chaque caractéristique produit une image filtrée avec des scores élevés et des scores faibles lors de la numérisation de l’image originale. Par exemple, la boîte rouge a trouvé quatre zones dans l’image originale qui correspondent parfaitement à la caractéristique, donc les scores sont élevés pour ces quatre zones. Les cases roses sont les zones qui correspondent dans une certaine mesure. Le fait d’essayer toutes les correspondances possibles en balayant l’image originale s’appelle la convolution. Les images filtrées sont empilées les unes sur les autres pour devenir la couche de convolution.
2. Couche ReLUs
L’unité linéaire redressée (ReLU) est l’étape qui est la même que celle des réseaux neuronaux typiques. Elle rectifie toute valeur négative à zéro afin de garantir le bon fonctionnement des mathématiques.
3. Couche de mise en commun max.

 testFigure (H)
testFigure (H)La mise en commun permet de réduire la taille de l’image. Dans la figure (H), une fenêtre de 2×2 balaie chacune des images filtrées et attribue la valeur maximale de cette fenêtre de 2×2 à une boîte de 1×1 dans une nouvelle image. Comme l’illustre la figure, la valeur maximale de la première fenêtre 2×2 est un score élevé (représenté par le rouge), donc le score élevé est attribué à la boîte 1×1. La case 2×2 se déplace vers la deuxième fenêtre où il y a un score élevé (rouge) et un score faible (rose), de sorte qu’un score élevé est attribué à la case 1×1. Après la mise en commun, une nouvelle pile d’images filtrées plus petites est produite.4. Couche entièrement connectée (la couche finale)

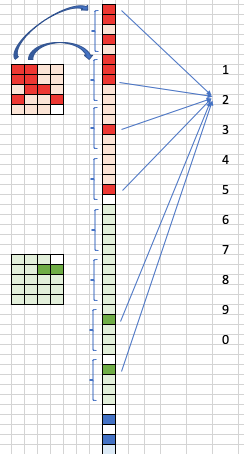
Nous divisons maintenant les petites images filtrées et les empilons en une seule liste, comme le montre la figure (I). Chaque valeur de la liste unique prédit une probabilité pour chacune des valeurs finales 1,2,…, 0. Cette partie est la même que la couche de sortie dans les réseaux neuronaux typiques. Dans notre exemple, « 2 » reçoit le score total le plus élevé de tous les nœuds de la liste unique. Ainsi, les réseaux de neurones reconnaissent l’image manuscrite originale comme étant « 2 ».
Quelle est la différence entre les CNN et les NN typiques ?
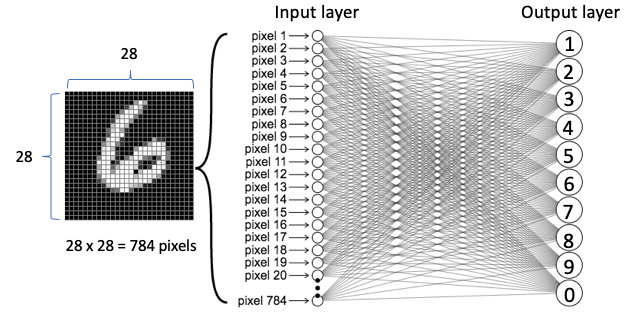
Les réseaux neuronaux typiques empilent l’image originale dans une liste et la transforment en couche d’entrée. L’information entre les pixels voisins peut ne pas être retenue. En revanche, les CNN construisent la couche de convolution qui retient les informations entre les pixels voisins.

Existe-t-il des codes CNN préformés que je peux utiliser ?
Oui. Si vous souhaitez apprendre le code, Keras dispose de plusieurs CNN préformés, notamment Xception, VGG16, VGG19, ResNet50, InceptionV3, InceptionResNetV2, MobileNet, DenseNet, NASNet et MobileNetV2. Il convient de mentionner cette grande base de données d’images ImageNet que vous pouvez contribuer ou télécharger à des fins de recherche.
Applications commerciales
La reconnaissance d’images a de nombreuses applications. Dans le prochain module, je vous montrerai comment la reconnaissance d’images peut être appliquée aux demandes d’indemnisation à traiter dans les assurances.
Pour plus de définition concernant la reconnaissnce d’image :














