Qu’est-ce que Mapreduce et comment fonctionne-t-il ?
MapReduce est le moteur de traitement d’Apache Hadoop, directement dérivé de MapReduce de Google. L’application MapReduce est écrite essentiellement en Java. Elle permet de calculer facilement d’énormes quantités de données en appliquant des étapes de mappage et de réduction afin de trouver une solution au problème posé. L’étape de mappage prend un ensemble de données afin de le convertir en un autre ensemble de données en décomposant les éléments individuels en paires clé/valeur appelées tuples. La deuxième étape de réduction prend la sortie dérivée du processus de mappage et combine les tuples de données en un ensemble plus petit de tuples.
MapReduce est un cadre de traitement extrêmement parallèle qui peut être facilement mis à l’échelle sur des quantités massives de matériel de base pour répondre au besoin croissant de traitement de grandes quantités de données. Une fois que les tâches de mappage et de réduction sont bien exécutées, il suffit de modifier la configuration pour qu’elles fonctionnent sur un plus grand data set. Ce type d’extensibilité extrême, d’un seul nœud à des centaines, voire des milliers de nœuds, est ce qui fait de MapReduce le favori des professionnels du Big Data dans le monde entier.
- Permet le traitement parallèle nécessaire à l’exécution des tâches liées au Big Data.
- Applicable à une grande variété d’applications de traitement de données commerciales
- Une solution rentable pour les cadres de traitement centralisé
- Peut être intégré à SQL pour faciliter les capacités de traitement parallèle.
L’architecture de MapReduce
L’ensemble du processus MapReduce est une configuration de traitement massivement parallèle où le calcul est déplacé à l’endroit des données au lieu de déplacer les données à l’endroit du calcul. Ce type d’approche permet d’accélérer le processus, de réduire la congestion du réseau et d’améliorer l’efficacité du processus global.
L’ensemble du processus de calcul se décompose en trois étapes : le mappage, le brassage et la réduction.
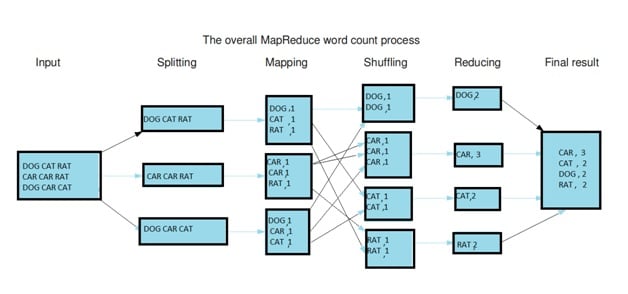
Étape de mappage : C’est la première étape de MapReduce et elle comprend le processus de lecture des informations à partir du système de fichiers distribués Hadoop (HDFS). Les données peuvent se présenter sous la forme d’un répertoire ou d’un fichier. Le fichier de données d’entrée est introduit dans la fonction de mappage, une ligne à la fois. Le mappeur traite ensuite les données et les réduit en blocs de données plus petits.
Phase de réduction : La phase de réduction peut se composer de plusieurs processus. Au cours du processus de brassage, les données sont transférées du mappeur au réducteur. Sans le brassage réussi des données, il n’y aurait pas d’entrée pour la phase de réduction. Mais le processus de brassage peut commencer avant même que le processus de mappage ne soit terminé. Ensuite, les données sont triées afin de réduire le temps nécessaire à la réduction des données. Le tri aide en fait le processus de réduction en fournissant un indice lorsque la clé suivante dans les données d’entrée triées est différente de la clé précédente. La tâche de réduction a besoin d’une paire clé-valeur spécifique afin d’appeler la fonction de réduction qui prend la clé-valeur comme entrée. La sortie du réducteur peut être directement déployée pour être stockée dans le HDFS.
Voici quelques-unes des terminologies utilisées dans le processus MapReduce :
- MasterNode – Lieu où JobTracker s’exécute et qui accepte les demandes de travail des clients.
- SlaveNode – C’est l’endroit où les programmes de cartographie et de réduction sont exécutés.
- JobTracker – Il s’agit de l’entité qui planifie les tâches et qui suit les tâches assignées à l’aide de Task Tracker.
- TaskTracker – Il s’agit de l’entité qui suit réellement les tâches et fournit le statut du rapport au JobTracker.
- Travail – Un travail MapReduce est l’exécution du programme Mapper & Reducer sur un ensemble de données.
- Task – L’exécution du programme Mapper & Reducer sur une section de données spécifique.
- TaskAttempt : tentative d’exécution d’une tâche particulière sur un SlaveNode.
Quel est le problème que MapReduce essaie de résoudre ?
MapReduce est directement issu de Google MapReduce qui était une technologie permettant d’analyser de grandes quantités de pages Web afin de fournir les résultats contenant le mot clé que l’utilisateur a recherché dans le champ de recherche de Google.
L’analyse des énormes quantités de données était auparavant une tâche herculéenne. MapReduce permet de travailler très facilement avec les Big Data et de les réduire en morceaux de données qui peuvent être facilement déployés pour n’importe quel objectif. Voici quelques-unes des caractéristiques uniques de MapReduce :
Il est très simple d’écrire des applications MapReduce dans le langage de programmation de votre choix, que ce soit en Java, Python ou C++, ce qui rend son adoption très répandue pour son exécution sur d’énormes clusters Hadoop. Il possède un haut degré d’évolutivité et peut fonctionner sur des clusters Hadoop entiers répartis sur du matériel de base. Il est hautement tolérant aux pannes et infaillible. Même si un nœud tombe en panne, ce qui est très probable en raison de la nature matérielle des serveurs, MapReduce peut fonctionner sans aucun problème puisque les mêmes données sont stockées à plusieurs endroits. Le calcul se déplace vers l’emplacement des données, ce qui est fortement recommandé pour réduire le temps nécessaire à l’entrée/sortie et augmenter les vitesses de traitement.
MapReduce apporte avec lui des capacités de traitement parallèle extrêmes. Il est déployé par des entreprises avant-gardistes de tous les secteurs industriels afin d’analyser d’énormes volumes de données à une vitesse record. L’ensemble du processus est simplement disponible par les fonctions de cartographie et de réduction sur du matériel bon marché pour obtenir un débit élevé. MapReduce est l’un des composants essentiels de l’écosystème Hadoop. Maîtriser le fonctionnement de MapReduce peut vous donner un avantage lorsqu’il s’agit de postuler à des emplois dans les domaines d’Hadoop.
Quel est le public visé par cette technologie ?
- Professionnels de la programmation Java et autres développeurs de logiciels
- Professionnels de l’ordinateur central, architectes et professionnels des tests
- Professionnels de la veille stratégique, de l’entreposage de données et de l’analyse.
- En quoi l’apprentissage de cette technologie sera-t-il utile à votre carrière ?
Le déploiement d’Hadoop est extrêmement répandu dans le monde d’aujourd’hui et MapReduce est l’un des moteurs de traitement les plus utilisés dans le cadre d’Hadoop. Ainsi, si vous maîtrisez cette technologie, vous pouvez obtenir un salaire élevé dans votre prochain emploi et faire passer votre carrière à l’étape suivante.
Si vous connaissez les subtilités du travail avec le cluster Hadoop et que vous êtes capable de comprendre les nuances de l’architecture MasterNode, SlaveNode, JobTracker, TaskTracker et MapReduce, leurs interdépendances et la façon dont ils fonctionnent en tandem pour résoudre un problème de Big Data Hadoop, alors vous êtes bien placé pour occuper des emplois bien rémunérés dans les meilleurs MNC du monde.
Quels sont les avantages de l’apprentissage de MapReduce ?
L’apprentissage de cette technologie présente de nombreux avantages. MapReduce est une façon très simplifiée de travailler avec des volumes de données extrêmement importants. Le plus intéressant est que l’ensemble du processus MapReduce est écrit en langage Java, qui est un langage très courant parmi les développeurs de logiciels. Il peut donc vous aider dans votre carrière en vous permettant de passer d’une carrière Java à une carrière Hadoop et de vous démarquer.
Vous aurez donc une longueur d’avance lorsqu’il s’agira de travailler sur la plate-forme Hadoop si vous êtes capable d’écrire des programmes MapReduce. Certaines des plus grandes entreprises du monde déploient Hadoop à des échelles jamais vues auparavant et les choses ne peuvent que s’améliorer pour les entreprises qui déploient Hadoop. Des entreprises telles qu’Amazon, Facebook, Google, Microsoft, Yahoo, General Electric et IBM utilisent des clusters Hadoop massifs afin d’analyser leurs quantités démesurées de données. En tant que professionnel de l’informatique à l’avant-garde, cette technologie peut vous aider à dépasser vos concurrents et à faire passer votre carrière à un tout autre niveau.














